Information Extraction using Convolutional Neural Network


Along the Ghats, Mathura by Edwin Lord Weeks
Technologies Used
- ✦ Python3
- ✦ Tensorflow
- ✦ Numpy
- ✦ Pandas
- ✦ Matplotlib
- ✦ Gensim
- ✦ NLTK
- ✦ Jupyter Notebook
Abstract
Text summarization is a technique of briefing a large text document by extracting its significant information. Extractive text summarization involves direct extraction of sentences from the original document to form a summarized document. The considered task had been an intriguing one for a long time and thus many approaches had been proposed for the same. This paper proposes information extraction from a large text document using a Convolutional Neural Network(CNN).
Introduction
The amount of information available online today is huge. Moreover, with the spread of the internet, it is now easy to share and avail any information. However, with this ease of availability of information, the problem of information overloading arises. Although data is available in abundance, it is hard to find whether it is reliable or not. Also, not everything in a document is required, a considerably large document might be filled with redundant data and thus only a portion of it contributes to actual information. Therefore, it becomes difficult to obtain the required and authentic information. Text summarization is a process by which the information content of a large document can be expressed by a comparatively smaller one about the significant information that was conveyed by the original document. It involves both Information Retrieval and Information Filtering [1]. Therefore, it can help obtain relevant information as well as time-efficient for tasks that involve a large amount of data. Text summarization can be further categorized [2] as extractive text summarization and abstractive text summarization. In extractive text summarization, the document is summarized directly by selecting and extracting relevant sentences and adding it to the generated summary. While, in abstractive summarization, the document under consideration is summarized by extracting the information semantically, i.e. to scan the document, understand its meaning and then the summary is generated according to the semantic knowledge of the document. Further, the summarization can be done for a single document or multiple documents. Or to say, text summarization can be done for a single document at a time or summarization of text can be performed considering multiple documents. The current paper proposes an approach of extractive method of text summarization for a single document and presents results obtained thereof. The proposed method uses a Convolution Neural Network based technique for extractive summarization of single documents. The document under consideration is converted to vectors embedding semantically meaningful word representations before summarization. The actual summarization uses pre-trained classes for processing by the CNN. Comparisons with blind summaries returned by human readers using BLEU returned good results. The rest of the paper has been organized as follows. The following section presents related work done on text summarization with section 3 presenting in brief the various techniques used. Section 4 presents the proposed model in detail and section 5 is dedicated to the experimentation and results. Finally, section 6 concludes the paper with discussions and future scope of work.
Related Work
Text summarization had been under consideration for quite a long time, with one of the earliest work done by H.P.Luhn[3] in 1958, which extracts statistical information using word frequency and distribution. Luhn approached the problem by marking the sentences according to the sum of the frequency of words in a document and then selecting and extracting the sentences having the highest score. Since then, various methods of ranking the sentences have been proposed, H.P.Edmundson[4] in 1969, proposed a similar ranking technique which along with the previously mentioned criteria of term frequency, also considered pragmatic phrase, words that appeared in the title as well as the location of the sentence in the document. The increasing availability of information kept text summarization relevant to researchers, and a lot of variety of techniques have been used to approach the problem. LF Rau et al. in 1989[5] approached the problem based on linguistic knowledge acquisition and using System for Conceptual Information Summarization, Organization, and Retrieval technique for text summarization. Todd Johnsan et al. in 2003[6] suggested generating a summary by creating a word graph based on similarity and removing the redundancy from the document. Also, Rada Mihelcea[7] in 2004 proposed an unsupervised graph-based ranking algorithm for sentence extraction from a text document. Another popular work of extraction of sentences was proposed by M.A.Fattah et al. in 2012[8] that considered the effect of summary features like the position of a sentence in the document, positive-negative keywords, similarity and many more. Then the features thus defined, were used with various advanced techniques, such as genetic algorithm, mathematical regression to generate feature weights, then neural networks and Gaussian Mixture model to perform summarization. Another similar but comparatively less complex work was proposed by M Mendoza Et al. in 2014[9] where similar sentence features were considered along with using genetic algorithms. The approach as the sentence extraction from text document is a binary optimization problem as assumed fitness to be dependent on various statistical features of the sentence. Text summarization has also been approached using neural networks by Aakash Sinha[10] in 2018. Neural networks in combination with other techniques are also been used for the problem under consideration, such as the idea of using neural networks with rhetorical structure theory was proposed by MK AR[11]. Not only combination techniques but also different variations neural networks have been used to approach the problem. Ramesh Nallapati et al. in 2017[12] in their work proposed using Recurrent Neural Networks to condense the text document. One another variation of Artificial Neural Network is Convolutional Neural Network(also popularly known as CNN). This paper proposes a model that incorporates CNN to extract information from a large text document, such that the extracted information alone can convey the significant idea portrayed by the larger text document.
Methodologies Used
1. Word Embeddings
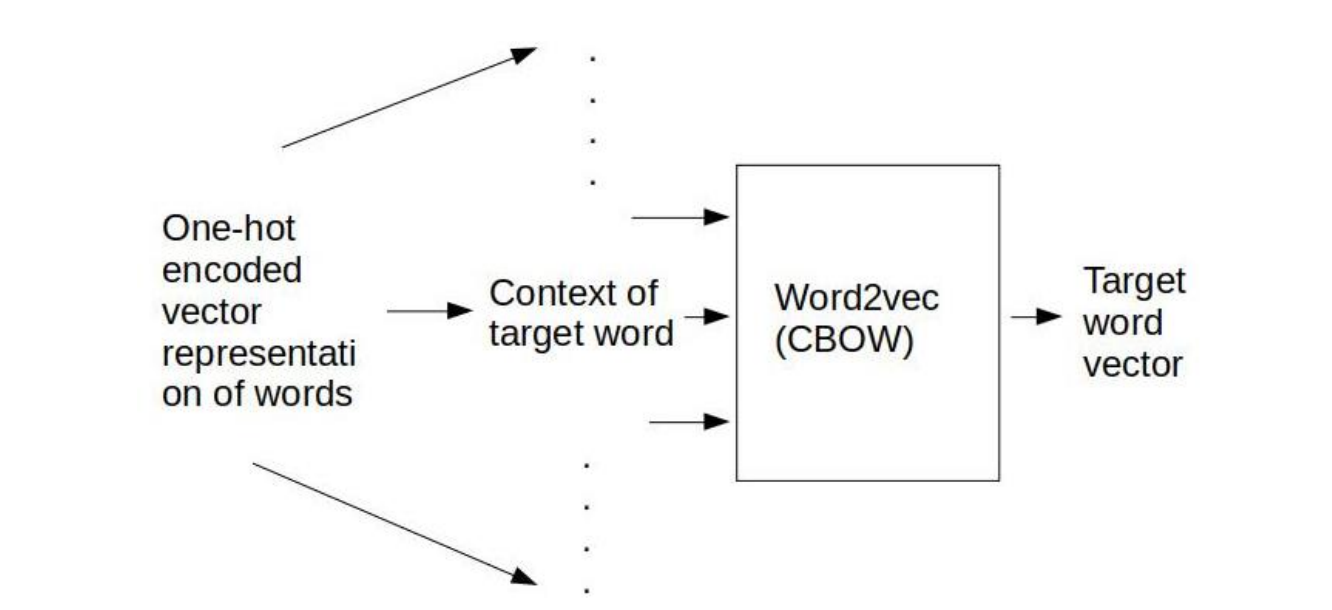
2. Convolutional Neural Network
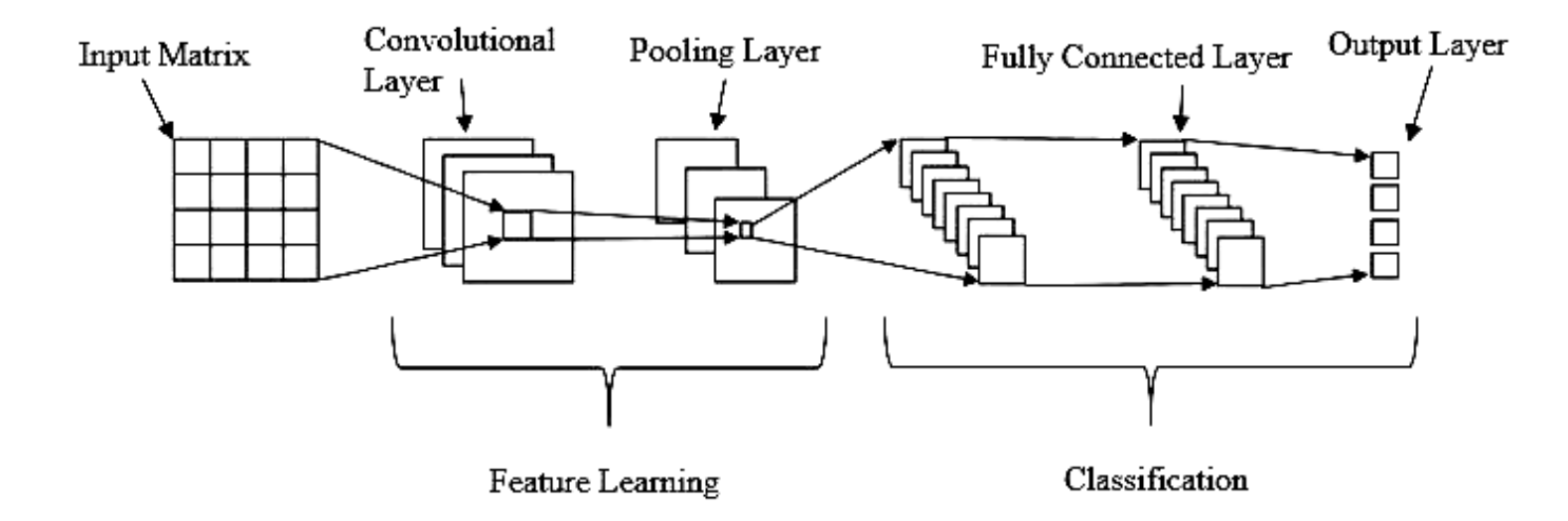
3. BLEU Score
Proposed Method
The model proposed in the paper had been experimented on three datasets, i.e. three documents were tried to be summarized using the proposed model. The documents thus considered had been different from one another in terms of its contents. The documents had information related to World War II [18], Sourav Ganguly [19] and Sir Aurobindo [20]. The first document had factual information about the events that occurred in World War II. The second document had information about Sourav Ganguly as a leader, and also his opinions on various events (in first person’s speech format). The third document consisted various quotes of Sir Aurobindo and Mother India. As no standard datasets were used for the task, data had to be pre-processed for further use as it had lots of noise. Various citations and other garbage symbols had to be removed, a more generalized form of the document was retrieved. Each sentence were then obtained and it was made sure no sentence were retrieved having number of words less than one, i.e. empty sentences that might appear due to direct retrieval from web pages are filtered. All the documents had to be cleaned and normalized for being fed into the model.
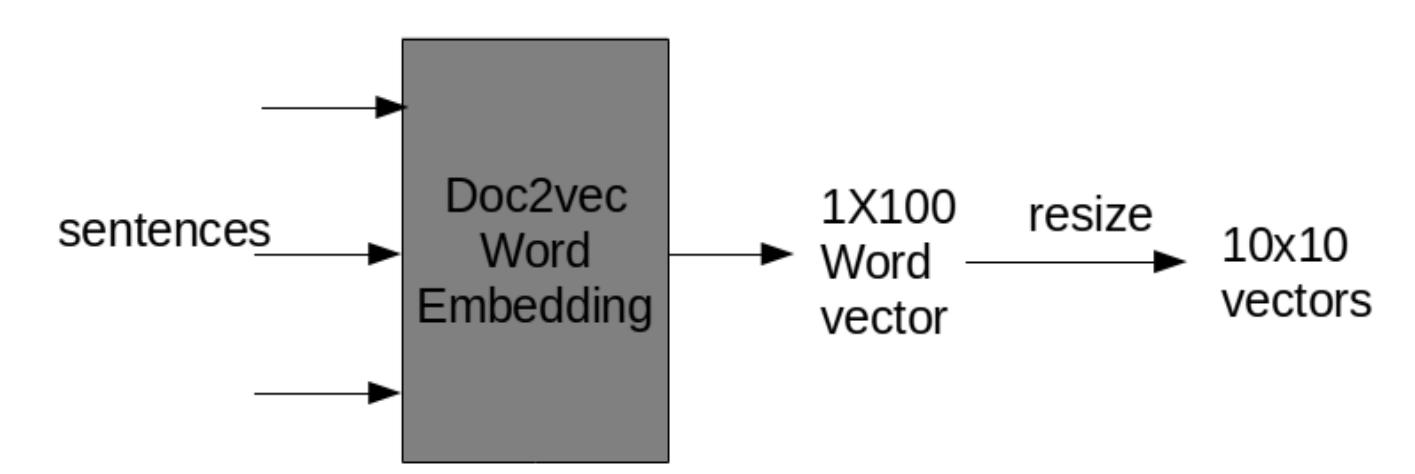
The documents had been carefully studied and various classes of sentences (information based) had been identified for each of the document. After identification of classes, a dataset had been so prepared that sentences falling under each class had been separated and kept under the heading of identified class. For instance, the document of World War II had sentences having information of events like its advancement, it impact in Asia and Europe, mass slaughter, causalities, aftermath and so on. Similarly, all the documents were studied carefully and sentences were classified manually. The paper proposes a model that uses neural network to perform the summarization task. But computations cannot be carried out directly over free text, the documents’ numerical representations had to be obtained and for the same, a neural model had to designed just to provide numerical representation of word. For the said task an embedding scheme had been adopted so that not just word vectors could be obtained, but the vectors even preserved semantic relations amongst them. The embedding technique used for this model was Doc2vec [21] as vectors were not required for each word, but for entire sentence. Each sentence being treated as individual documents were embedded and equivalent vector representations were retrieved. As the document had sentences ranging from very short sentences to long running sentences, vector size was fixed to 100, assuming no important information will be lost nor too much void information will be stored. However, as the model proposed in the paper primarily uses CNN for summarization, the vectors were resized to its 2D equivalent matrix of size 10x10 as the model was seen to perform better with 2D representation as compared to single dimension representation. The sentence vectors thus obtained are now to be fed into another neural network for training purpose. As said, the documents had been refined and various classes of sentences were identified based on its information. In accordance to these defined classes the sentence vectors had to be trained and for this training purpose, a convolutional neural network(CNN) model is proposed. To avoid early shrinking, the model employed a zero padding layer at the beginning of the architecture, followed by a convolutional layer and max pooling layer respectively. But the model uses three parallel architectures for said padding, convolution and pooling task as the classification task is expected to be better achieved with such architecture [22]. The results of these parallel architectures had to be concatenated to unite the results. After concatenating the results, a flatten layer had been deployed to flatten the outcome of its previous layers removing the insignificant entries. Finally, a dense layer, or to say, a fully connected layer was deployed to complete the classification task. The model uses Rectified Linear Unit (ReLU) as its activation function in the convolution layer. The activation function gives same value as input if positive else returns zero. It is said to be one of the most used activation function for CNN architectures [23]. But, this activation function has a limitation that it cannot be used in output layer. For the output layer, since the network deals with multi classification task of sentences, the activation of softmax have been used. The activation function so works that it gives probability of each sentence for each class and all these probabilities sums to one. To track the loss of the network while training, loss function of sparse categorical cross entropy [24] is used. The output of this loss function ranges between 0 and 1, and this value is actually in the probability form. As known, loss function is an error reduction method of the network. The generated output is actually the difference between predicted probability and expected probability for the classification task and thus the correction process aims at depleting this difference.
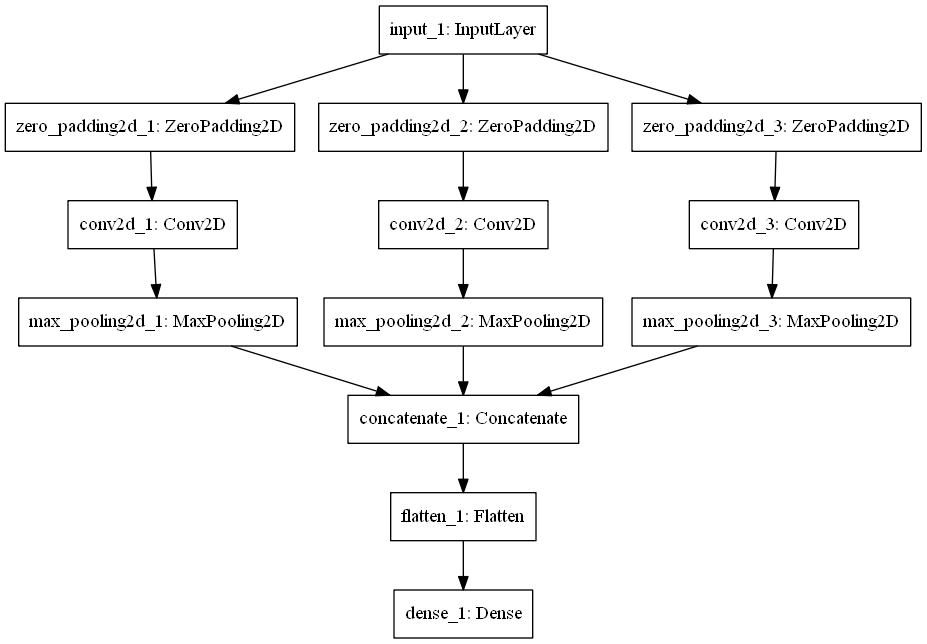
The architecture of CNN used is a sequential one. However, as the documents are of different type, the architecture had to undergo some changes in order to obtain better results. For instance, since the document of World War II contains simple factual data about the events that occurred during the war period, not many changes had to be done for this dataset. The figure below roughly demonstrates the architecture of World War II data. However, this is not the case with the other datasets. As document containing the data regarding Sourav Ganguly had first person’s speech and that having data related to Sir Aurobindo consisted series of quotes, it had been comparatively complex to summarize the data as compared to the earlier mentioned dataset. Thus for these datasets, an addition pooling layer had to be deployed for better results. Figure 5 graphically represents this architecture.
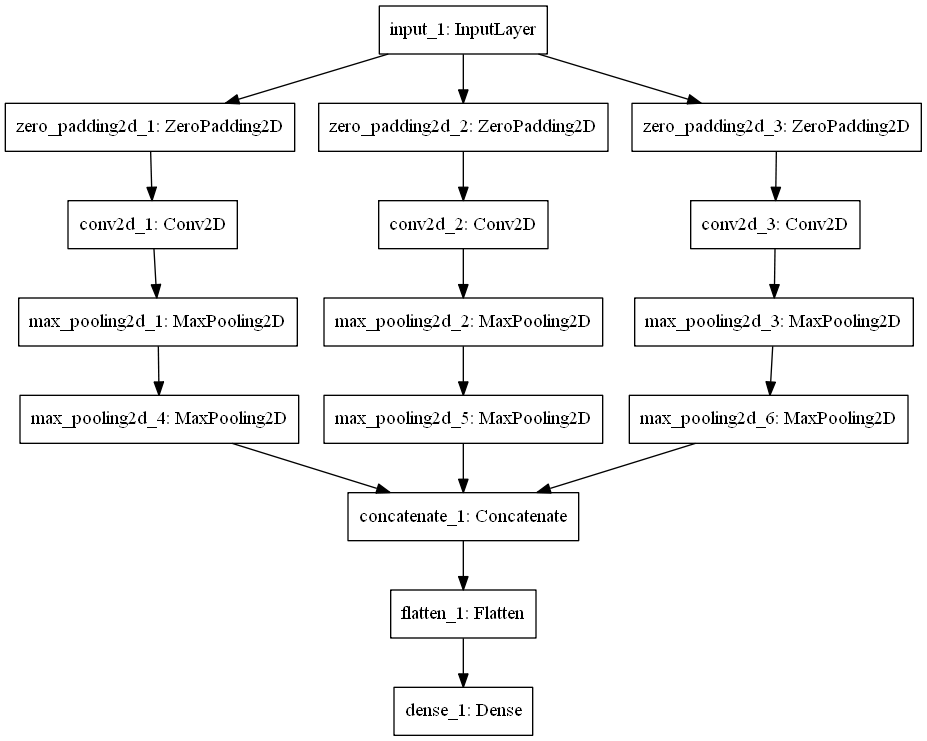
Using the said architecture, the document is first trained about the sentences falling under specified classes. The network is trained, weights adjusted with each iteration, loss decreased and accuracy is enhanced. Once the network had been trained, the document is given as input, sentences are separated, it is vectorized and then classification is carried out. The input document is divided into set of sentences each classified into designed classes. After classification is done, the first sentences are picked from each class assuming that the first sentence cannot be skipped for summary generation else entire context of the class will be ambiguous. The process of selection of sentences is carried on until the summary is so generated that the size of summary is 30% of that of the size of original document.
Experiment and Results
The evaluation of the machine generated summary is not very deterministic task [25]. The correctness of summary may differ from person to person depending upon an individual’s own perspective. Yet attempts were made to try evaluating the generated summary (the candidate summary) with reference to some human generated summary (the reference summary). Four reference summaries were considered for each of the document and evaluation was carried to check the efficiency of the build model. For evaluation of the machine generated summary, the matrix of BLEU is been used. Usually, the BLEU score of less than 15(if scaled out of 100) is said to be bad score while more than 35[26] is acceptable. The scores obtained for each dataset against each reference summary is gin in the tables below:
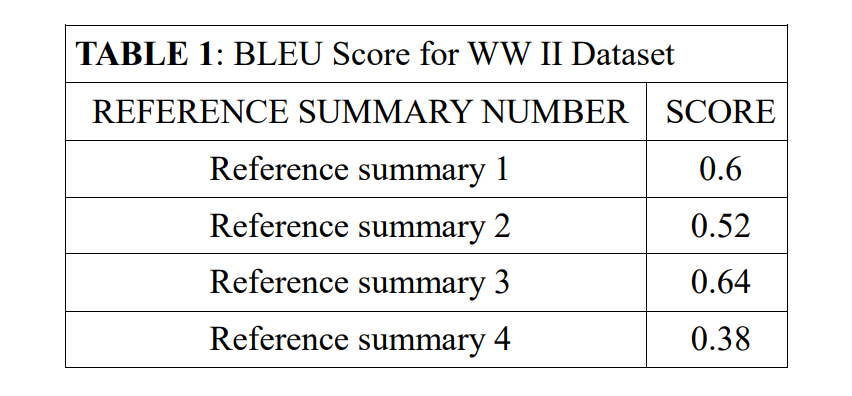
Table 1, presents results that can deduce that reference summary 3 is most similar to that of machine generated summary, while reference summary 4 is most distinct. Thus it is difficult to say about the correctness of the summary as the same machine generated summary seems to be good for one human while not that efficient for the other one.
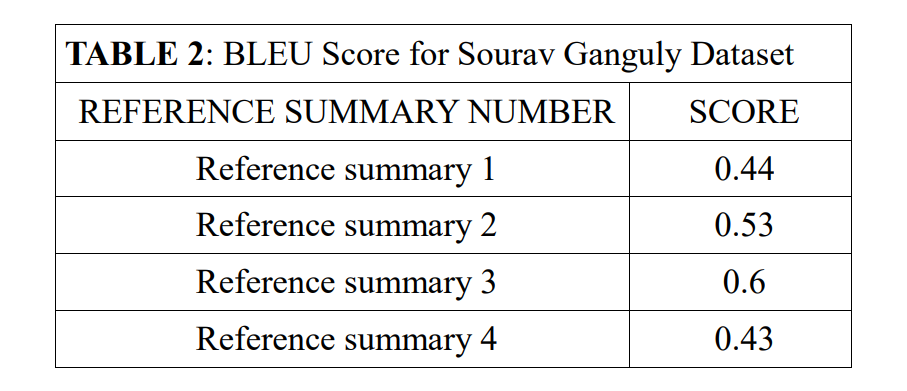
Analyzing Table 2, it can be said that if the generated summary is considered in context of reference summary 3, it is an appreciable model; but again it is not that good when considered with context of reference summary 4. Also, it can be seen that the results for first dataset had been quite better than this dataset.
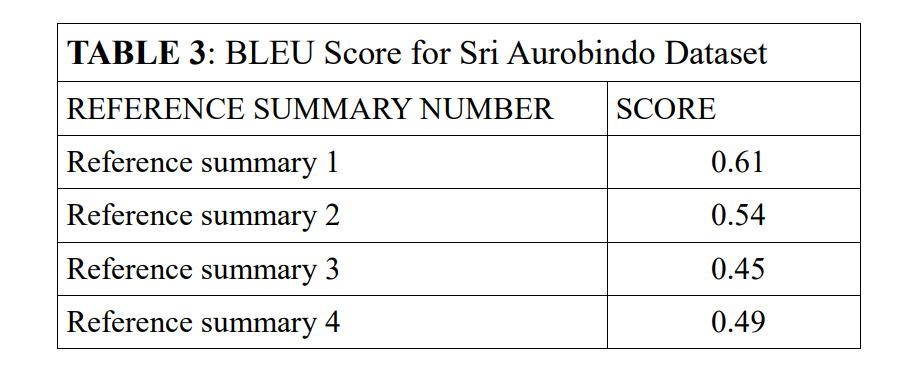
Analysis of data shown in Table 3, in reference to reference summary 1 the model is seen to provide best result while the same is not the case for reference summary 3. Again, it is clear that the model does not always provide best results for same reference set. That implies, for same human, the summary generated by the model may be really appreciable for one document but this might not be the case every time. The considered for evaluation is BLEU. However, BLEU is usually used for evaluation of machine translation. Therefore for better understanding for the performance of the designed model, a confusion matrix is created to map the common sentences, it frequency in the candidate summary and the reference summary. As already mentioned, the summarization task is so carried by the model that it condenses the original document to 30% of its size. Thus reference summaries were also so designed that it included the sentences from the document and the size ratio was maintained. The documents considered for summarization were condensed to be:
- ✦ World War II document – 13 sentences
- ✦ Sourav Ganguly document – 17 sentences
- ✦ Sir Aurobindo dataset – 9 quotes
The confusion matrix for common sentences in candidate summary and reference summary thus created is shown in the Figures 6, 7 and 8 for document related world war II, Sourav Ganguly and Sir Aurobindo respectively.
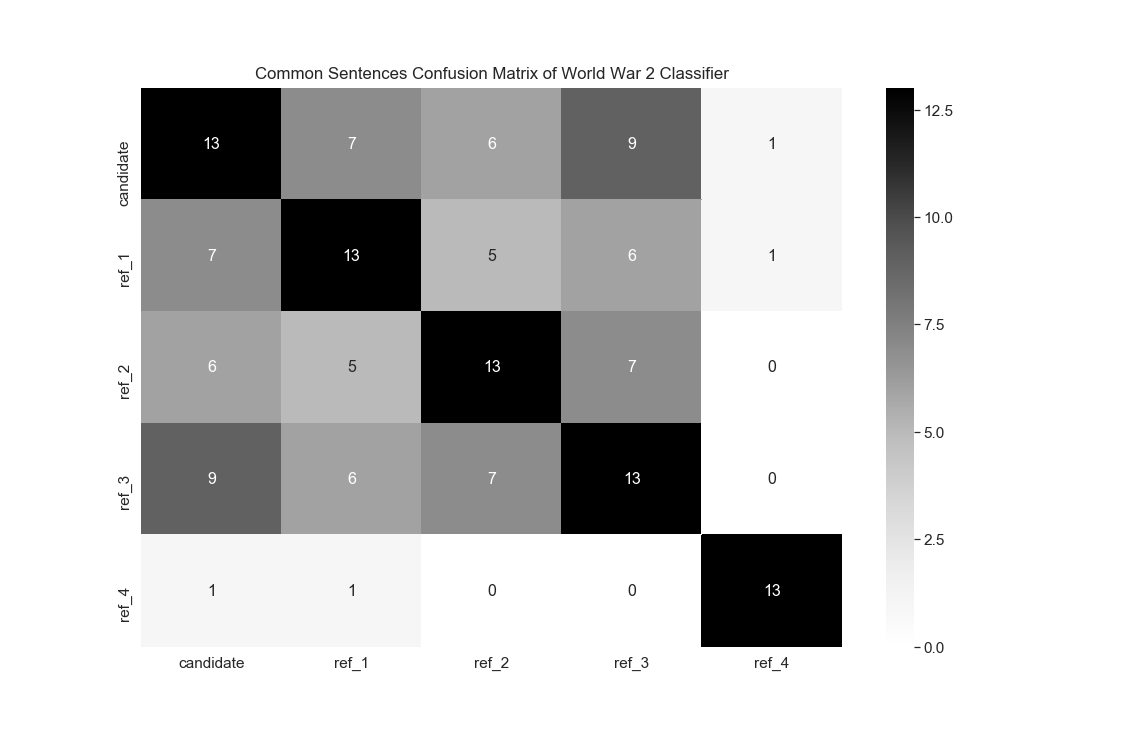
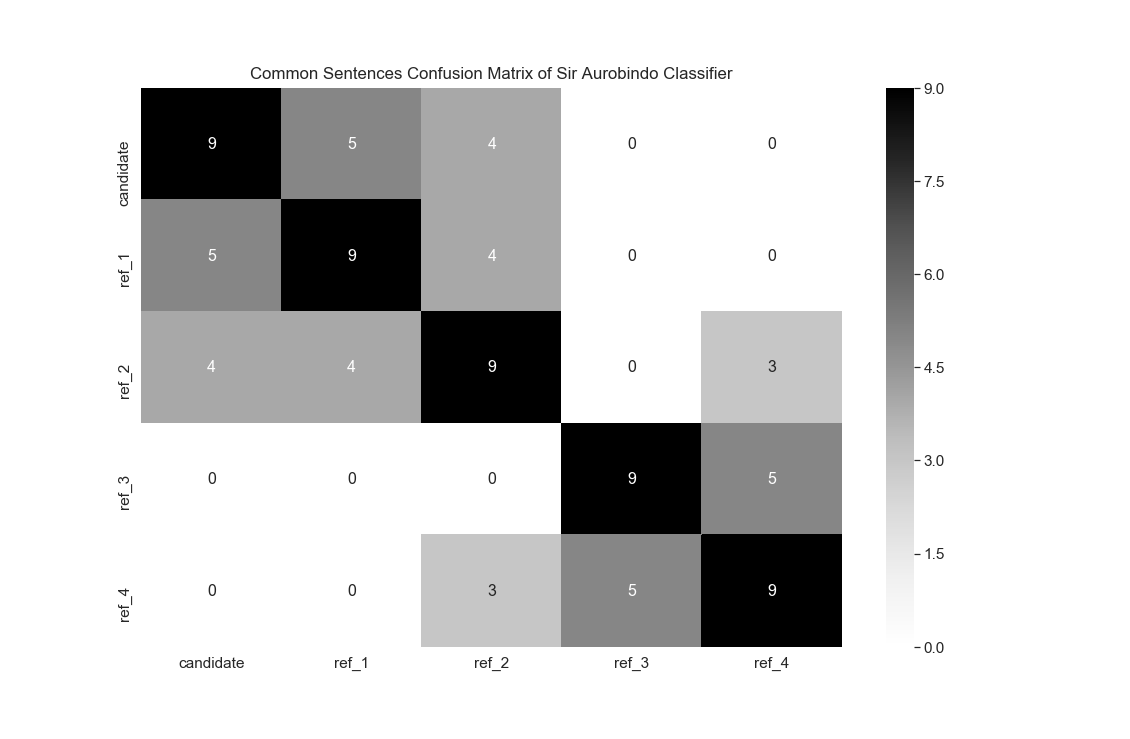
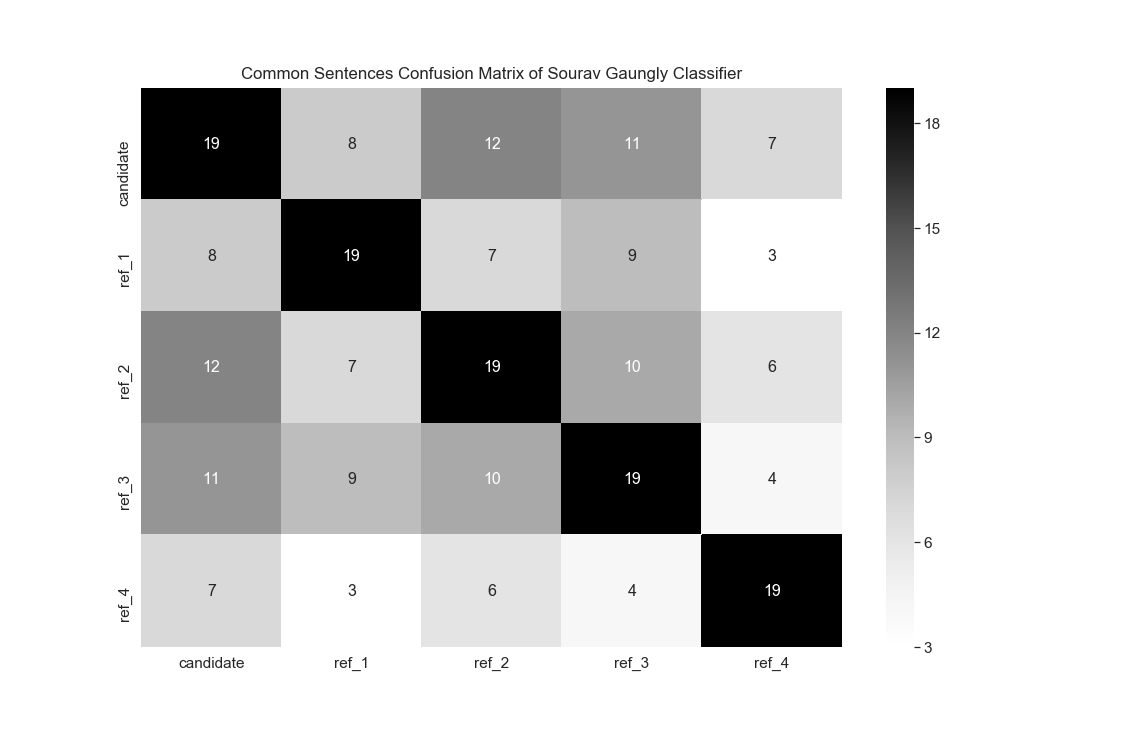
But the accuracy of the candidate summary is still not deterministic. Similar to BLEU score there is no consistency in the pattern of occurrence of common sentences in the candidate and reference summary. Rather, no such consistency can be observed in the reference summaries themselves. Hence, the context of evaluation in such task cannot be fixed and therefore it is dependent on an individual whether the summary generated is acceptable or not.
Conclusion
The model proposed in this paper prepares a summary of text data by using neural network architecture, widely using Convolutional Neural Networks. Firstly, the input documented is numerically represented using word embedding technique of Doc2Vec. The vectors from said architecture is then retrieved and fed into another CNN model where classification task is carried on. After classification of sentences in relevant classes designed in accordance of the document, sentences are retrieved from each class and the summary is generated which condenses the original document to 30% of its actual size. The summary thus generated was then evaluated against human generated reference summaries and it had been found that a simple architecture can generate appreciable results with acceptable computational complexity. However, using CNN makes the model significantly supervised. Thus, for generation of summary using this architecture is possible only when the model can be trained well and this training again involves proper designing of class and rectification of data. But, once the model is trained well, it is expected that it can well summarize any document of that domain.
Keywords:
- ✦ Extractive summarization
- ✦ Embeddings
- ✦ Doc2Vec
- ✦ Convolutional Neural Network
- ✦ BLEU