Trusting the Machine: Cross-Validating LLM Output With a Second Model


Nighthawks by Edward Hopper
There is a particular kind of bug that I find genuinely unsettling. It is not the loud kind that crashes the build and wakes you up at 3 am. It is the quiet kind, where everything runs fine, the dashboard stays green, the data looks completely reasonable, and it is still wrong.
When you hand a language model the job of reading documents and pulling out structured data, you make room for exactly this kind of bug. The model reads a page, fills in your fields, and returns clean JSON. It looks like magic, and honestly most of the time it is. But once in a while it invents a number that was never on the page, or skips a value it should have caught. You get no exception and no stack trace, just a small, plausible mistake sitting in your database and quietly poisoning everything that depends on it.
For a while I did what most people do. I wrote a stricter prompt, added a schema, and hoped for the best. That got me part of the way, but it never really solved the problem. So I tried asking a different question. Instead of "how do I make one model more reliable," I asked myself how a careful team of people would actually handle this.
The answer was obvious the moment I phrased it that way. You get a second opinion.
The Trouble With One Opinion
A single model has no real sense of when it is wrong, and that is not something you can fix with a better prompt. It is just how the thing works. The model produces whatever continuation seems most plausible, and a plausible-sounding fabrication is precisely the case it is worst at noticing on its own.
You, the engineer, are not in a much better position. You were not there when it read the document, and if you had the time to check every extracted value against the source by hand, you would not have reached for a model in the first place. So the output shows up in perfect formatting, and you have no particular reason to distrust any one field. The better the model gets at looking right, the harder it becomes to tell when it actually isn't.
What you really want is a signal that does not come from the model at all. Something produced by a completely different process, so that when the two of them line up you have reason to believe them, and when they clash you know exactly where to look.
The Second Opinion
The idea itself is simple. Run the extraction more than once, through genuinely different paths, and compare the results one field at a time. Where they agree, you have evidence. Where they disagree, you have something worth a human's time.
None of this is a new idea, most of us already do it all the time. I will sketch out an architecture or a chunk of code with one model, then paste it into a different one and ask it to find the holes. The second model usually catches something, not because it is smarter, but because it is coming at the problem fresh and has no attachment to the first answer. All I really did here was take that everyday habit and wire it into the pipeline, so it happens on every single record automatically instead of only when I remember to ask.
Here is the whole thing in one picture:
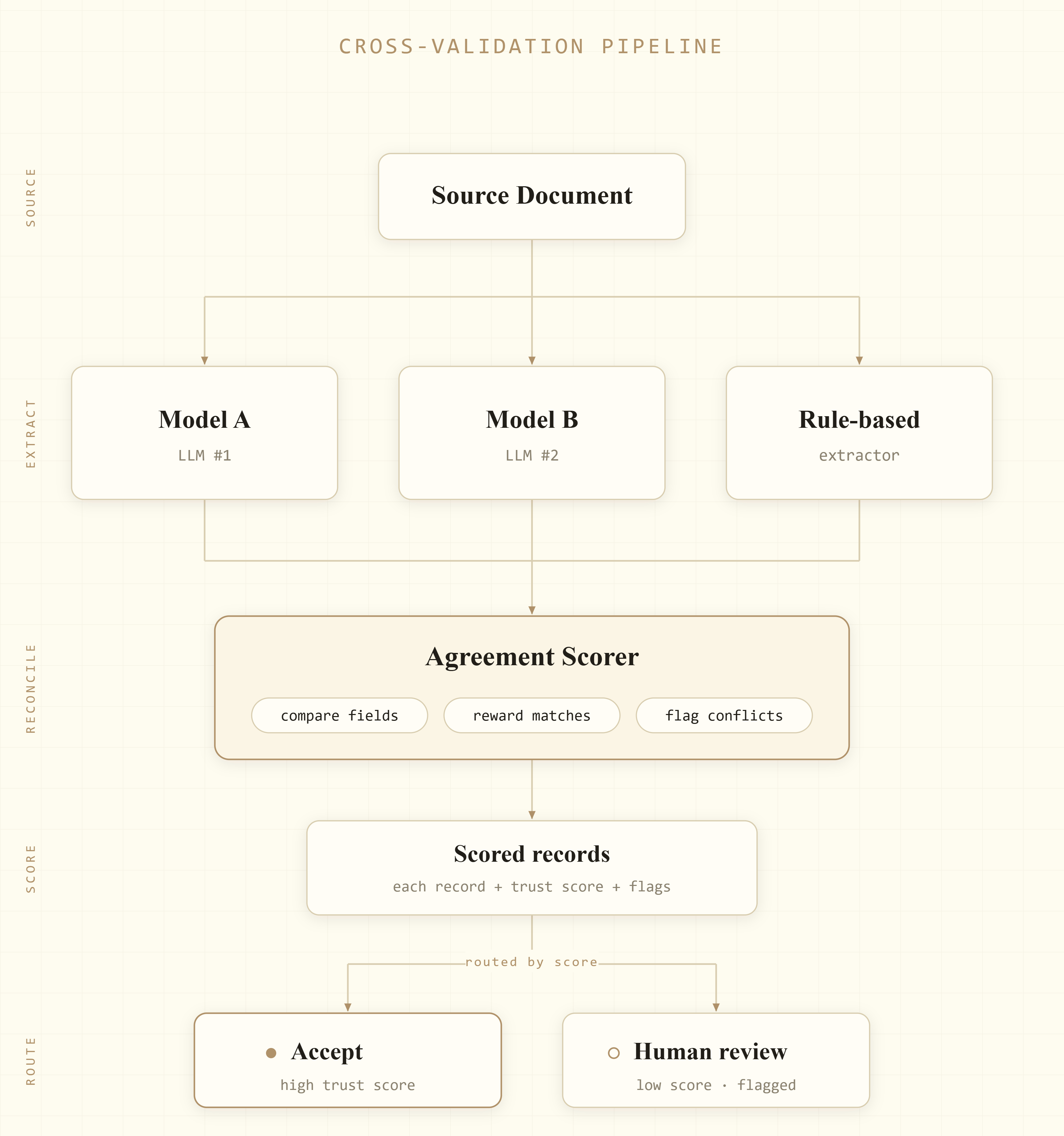
Three extractors, each with its own way of being right and wrong, and one scorer that holds their answers up against each other.
Three Cheap Checks
The whole thing only works because the three paths fail in different ways. If they all made the same mistakes, comparing them would tell you nothing, so I went out of my way to pick methods whose blind spots do not overlap.
The first check is one model against another. Two different language models read the same document, and when both independently land on the same value for a field, that is a strong sign it is real, because they are very unlikely to invent the same fabrication. When they disagree, the field gets flagged. This is what catches the confident invention a single model would have walked right past.
The second check is the model against rules. A plain, old-fashioned extractor (regular expressions, mostly) runs over the same text looking for numeric values. It is much dumber than the model and it misses plenty, but whatever it does catch, it catches without any imagination at all. It cannot hallucinate, so when the model's number and the rule's number agree, that is a completely different kind of confirmation.
The third check is the model against grounding. The entities the model claims to have found get compared against an independent list of what actually appears in the document. If the model reports something the document never mentions, that is a strong hint it made it up, and the field gets flagged.
On its own, each check is weak. Put together, they act like a net. A value that clears all three has earned its spot in the database, and a value that trips any of them gets a person's attention. The nice part is that only those values do, so a reviewer's time goes straight to the places that actually need it.
From Agreement to a Number
Flags on their own are not quite enough. You want a dial, not just an alarm. So each record starts from the model's own stated confidence and gets nudged up or down from there: a small bump when an independent source agrees, a bigger drop when one disagrees, and a plain-English note attached to every adjustment so you can see why.
What comes out is a single trust score per record, along with the reasons behind it. That score is what lets the system mostly run itself. High-confidence records flow straight through, and the handful that disagree get pushed to a person with the conflict already spelled out, something like "model A said 872, the rules said 745, that is a 17 percent gap." A review like that takes seconds instead of minutes. You are no longer checking everything, only the things the machines could not agree on.
The Part That Surprised Me
The hard part was not the comparison itself. It was figuring out which two things to compare in the first place.
Before you can ask whether two models agree on a record, you have to be sure they are even talking about the same record. When a document describes several similar items, each model lists them in its own order and uses slightly different names for each one. Match them up wrong and your carefully built scorer ends up comparing one item to a different one, and then it reports nonsense: disagreement where there is none, and false confidence exactly where you should be worried.
That quiet matching step, which has the proper name of entity resolution, is where most of the actual engineering went. It was a good reminder that in systems like this the intelligence is rarely the bottleneck. The plumbing around the intelligence usually is.
The Takeaway
One model gives you an answer. A second, independent path gives you something more useful, which is a reason to believe that answer or a reason to doubt it. Most of the effort in this project did not go into getting a good answer out of a model. It went into earning the right to trust it.
If you are putting a language model into anything where a quiet mistake is expensive, do not bet on one model being perfect. Set up two imperfect processes, let them disagree, and pay close attention when they do. That disagreement is not noise. It is probably the most honest signal you have.